
Afin d'améliorer la mobilité et de renforcer la sécurité sur les autoroutes, nous avons opté pour une solution permettant la détection et la classification des véhicules (selon leur taille) à partir des images prises en utilisant des caméras fixes dans une autoroute. Les résultats ainsi trouvés pourront servir comme un outil d'aide à la décision pour les gestionnaires du traffic routier afin de prendre les mesures adéquates visant à équilibrer l'offre avec la demande du trafic. En effet, ceci peut être réalisé à travers deux techniques: soit à l'aide des modèles du Deep Learning ou bien à l'aide des techniques de traitement d'images. Néanmoins, nous nous limiterons dans ce projet à l'utilisation de quelques algorithmes de l'IA.
Détection et classification des véhicules selon leur longueur en utilisant plusieurs modèles: Yolov5, CNN, Faster-RCNN, Detectron…

Pour ce faire, on va faire recours à Roboflow. En effet, Roboflow est une plateforme dédiée à la
Computer Vision permettant de faire la détection, la segmentation
et la classification des objets.

Afin de mieux comprendre le fonctionnement de nos propres solutions qui sont basées sur des algorithmes de Deep Learning, nous allons tout d'abord définir respectivement ce que c'est que La computer vision, l'IA, le machine Learning , le Deep Learning et finalement le réseau des neurones.
La vision par ordinateur ou encore appelée Computer Vision est un domaine des sciences de l'informatique qui permet aux ordinateurs et aux systèmes de dériver des informations significatives à partir d'images numériques, de vidéos et d'autres entrées visuelles afin de prendre des mesures ou de faire des recommandations sur la base de ces informations. Son objectif est d'imiter le système visuel humain comme le montre la figure ci-dessous:
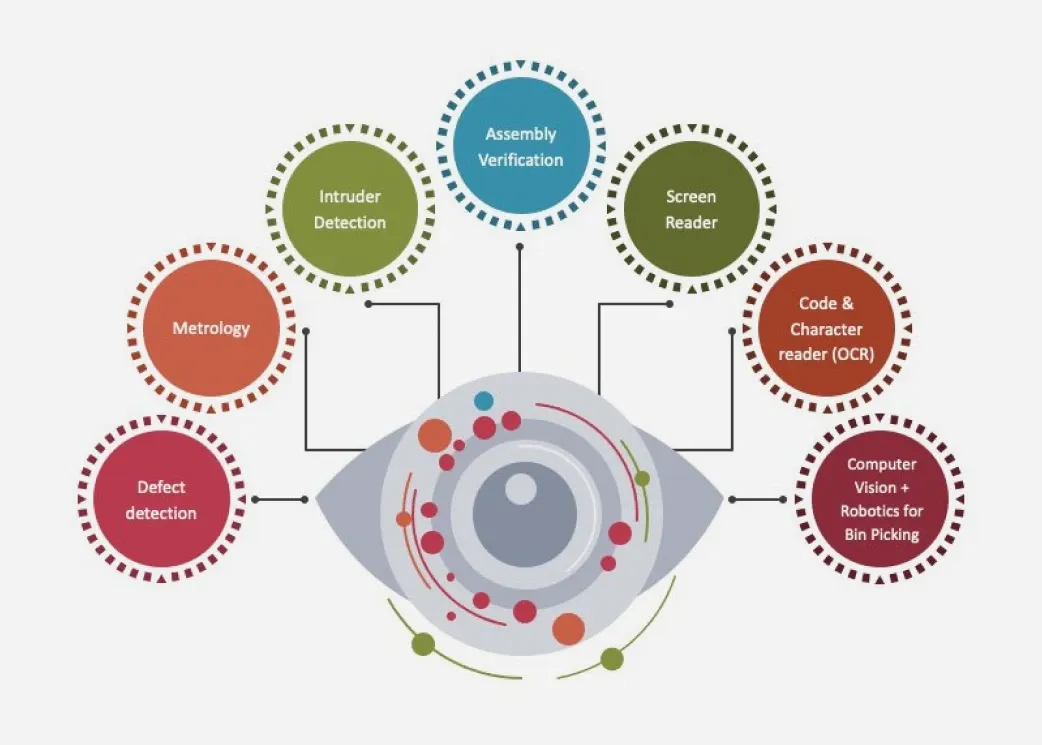
L'intelligence artificielle, désigne les systèmes ou les machines qui imitent l'intelligence humaine pour effectuer des tâches et qui peuvent s'améliorer de manière itérative en fonction des informations qu'ils recueillent.Elle englobe également les sous-domaines de l'apprentissage automatique et de l'apprentissage en profondeur qui sont fréquemment mentionnés en association à l'intelligence artificielle. Ces disciplines sont composées d'algorithmes d'IA qui cherchent à créer des systèmes experts qui exécutent des prévisions ou des classifications sur la base de données d'entrée.
La figure ci-dessous montre la relation entre l'IA, le Machine Learning et le Deep Learning.
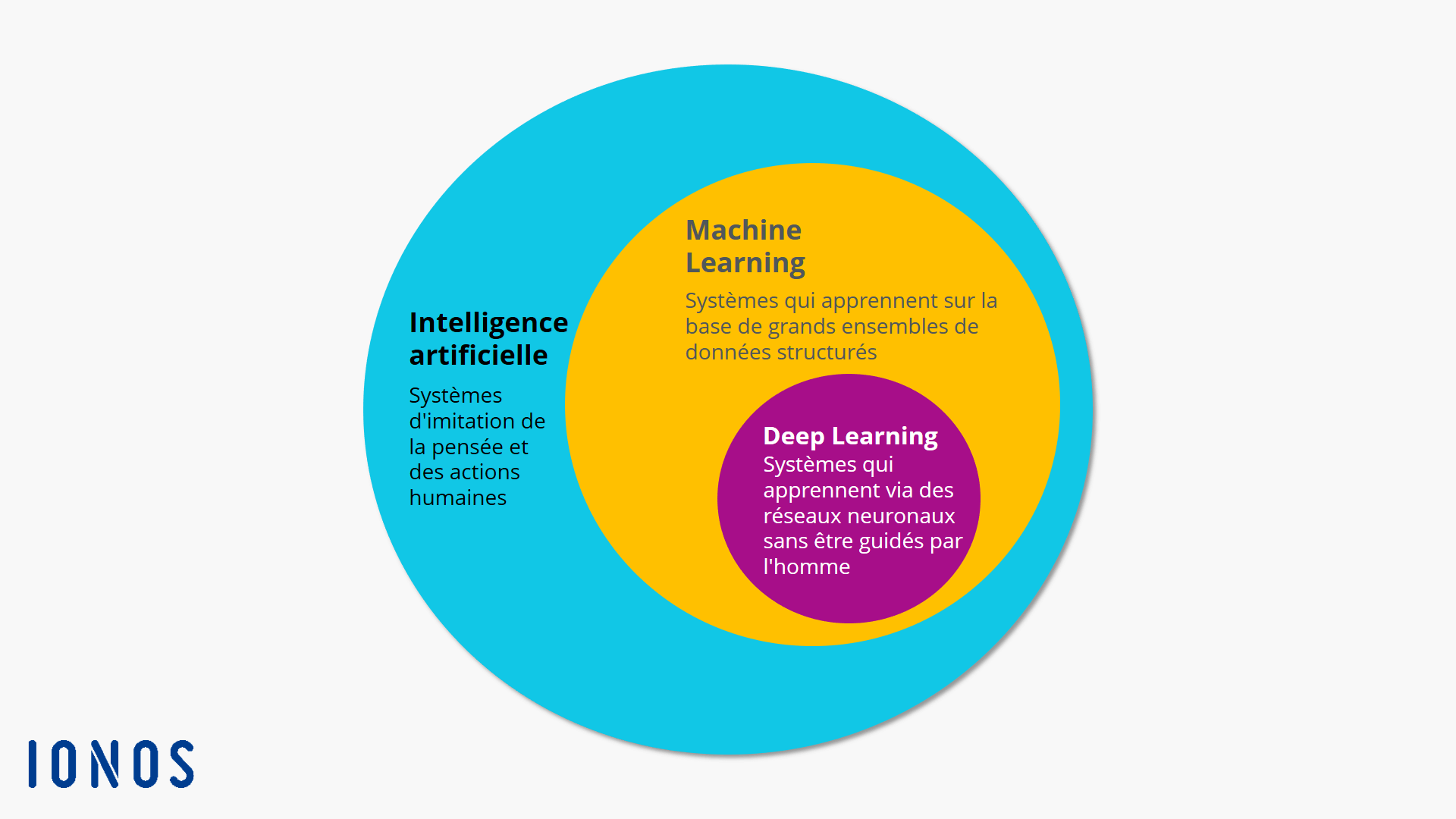
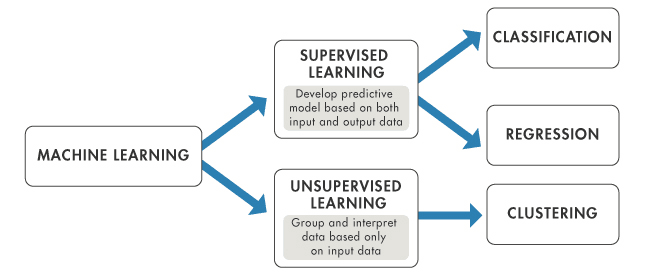
L'apprentissage automatique est une branche de l'intelligence artificielle qui se concentre sur l'utilisation de données et d'algorithmes pour imiter la façon dont les humains apprennent, améliorant progressivement sa précision.
L'apprentissage profond ou encore Le Deep Learning est une branche du Machine Learning qui repose sur l'utilisation des réseaux neuronaux artificiels permettant ainsi aux systèmes numériques de comprendre des données non structurées et non étiquetées avec précision tout en les analysant à un haut niveau d'abstraction grâce à une compréhension non linéaire.

Un réseau de neurones artificiels, est un système informatique matériel et / ou logiciel dont le fonctionnement est calqué sur celui des neurones du cerveau humain. Il existe plusieurs types de réseaux de neurones: on en distingue le CNN (Le réseau des neurones de convolution), le RNN ( réseau de neurones récurent) ainsi que Le GAN (réseau de neurones antagoniste génératif) etc.

Les réseaux de neurones artificiels souvent appelés «ANN » sont constitués de différentes couches de nœud (ou neurone artificiel), contenant une couche en entrée, une ou plusieurs couches cachées et une couche en sortie. Chaque nœud, se connecte à un autre et possède un poids et un seuil associés. Si la sortie d'un nœud est supérieure à la valeur de seuil spécifiée, ce nœud est activé et envoie des données à la couche suivante du réseau. Sinon, aucune donnée n'est transmise à la couche suivante du réseau. Chaque nœud individuel peut être considéré comme étant son propre modèle de régression linéaire, composé de données d'entrée, de poids, d'un biais (ou d'un seuil) et d'une sortie.
Après avoir défini ce que c'est qu'un réseau de neurones et après avoir cité quelques exemples de l'ANN dans les sections qui précédent, nous nous limiterons dans cette section à l'explication du CNN.En effet, le réseau de neurones convolutif désigne une sous-catégorie de réseaux de neurones. Cependant, le CNN est spécialement conçu pour traiter des images en entrée.Son architecture dispose en amont d'une partie convolutive et comporte par conséquent deux parties: Une partie convolutive et une partie de classification.
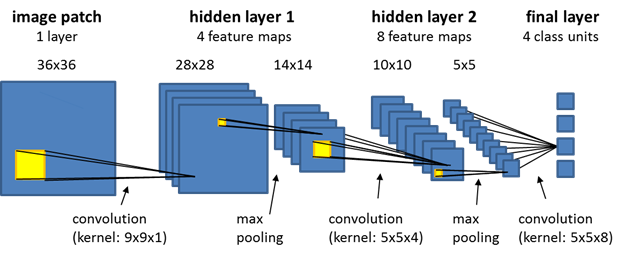
La partie convolutive:
Son objectif est d'extraire des caractéristiques propres à chaque image en les compressant de façon à réduire
leur taille initiale sans pour autant perdre les caractéristiques les plus importantes. L'image fournie en
entrée passe à travers une succession de filtres, créant de nouvelles images appelées cartes de
convolutions qui seront après concaténées dans un vecteur de code CNN.
La partie de classification:
Le code CNN obtenu en sortie de la partie convolutive est fourni en entrée dans une deuxième partie, constituée
de couches entièrement connectées appelées perceptron multicouche (MLP pour Multi Layers
Perceptron). Le rôle de cette partie est de combiner les caractéristiques du code CNN afin de
classer l'image.
La méthode YOLO divise l'image en N grilles, chacune
avec un secteur dimensionnel SxS de taille égale. Chacune de ces N grilles est chargée de détecter
et de localiser l'objet qu'elle contient tout en prévoyant les coordonnées de la boîte englobante B
par rapport aux coordonnées de la cellule, ainsi que le nom de l'élément et la probabilité que l'objet soit présent
dans la cellule. YOLO se compose d'un total de 24 couches convolutives dont les 20 premières sont
pré-entraînées sur l'ensemble de données de classification ImageNet 1000-class et les quatre dernières sont suivies
par deux couches entièrement connectées permettant ainsi d'entraîner le réseau à la détection d'objets avec notre
base de données.
Les versions de YOLO utilisées dans notre projet sont:
Pour utiliser l'une de ces versions il faut:
# clone YOLOv5 repository
!git clone https://github.com/ultralytics/yolov5 # clone repo
%cd yolov5
!git reset --hard fbe67e465375231474a2ad80a4389efc77ecff99
Exemple:
!pip install -q roboflow
from roboflow import Roboflow
rf = Roboflow(model_format="yolov5", notebook="roboflow-yolov5")
%cd /content/yolov5
rf = Roboflow(api_key="YOUR API KEY HERE")
project = rf.workspace().project("YOUR PROJECT")
dataset = project.version("YOUR VERSION").download("yolov5")
%%writetemplate /content/yolov5/models/custom_yolov5s.yaml
# parameters
nc: {num_classes} # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
# train yolov5s on custom data for 100 epochs
# time its performance
%%time
%cd
!python train.py --img 416 --batch 16 --epochs 100 --data {dataset.location}/data.yaml --cfg ./models/custom_yolov5s.yaml --weights '' --name yolov5s_results --cache
On peut également changer les paramètres suivant pour faire de l'apprentissage:
%reload_ext tensorboard
%tensorboard --logdir runs
Exemple:
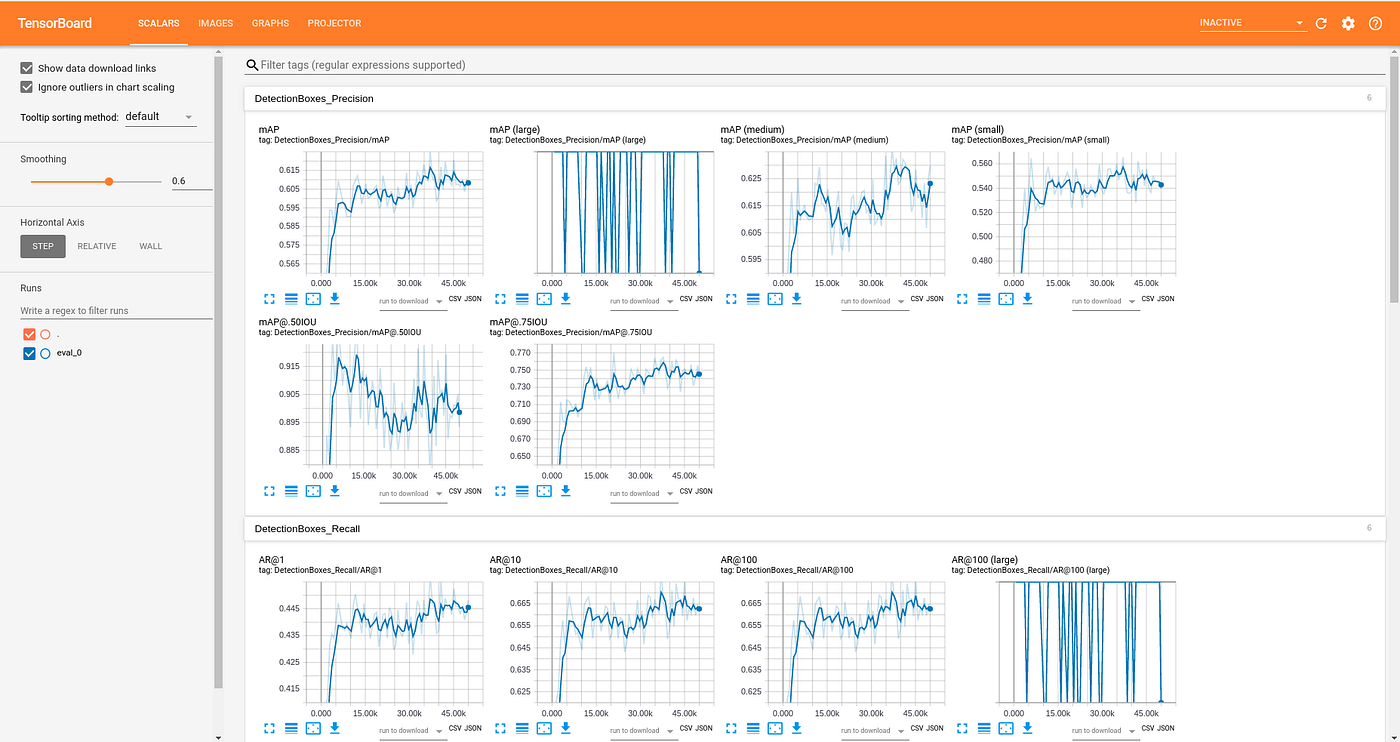
Ce Tensorboard permet de nous afficher les courbes et les mesures des différents paramètres permettant ainsi de définir le degré de précision du modèle utilisé pour l'apprentissage.
# when we ran this, we saw .007 second inference time. That is 140 FPS on a TESLA P100!
# use the best weights!
%cd /content/yolov5/
!python detect.py --weights runs/train/yolov5s_results/weights/best.pt --img 416 --conf 0.4 --source /content/testvid/BackVehcilesTraffic1080p.mp4
Exemple:
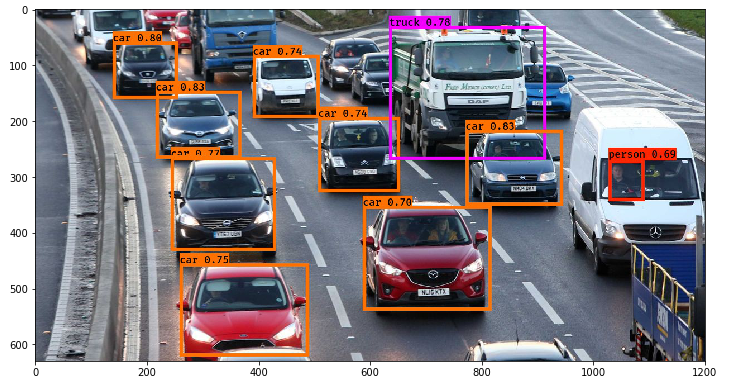
Après avoir testé le modèle YOLOv5, YOLOv6 et
YOLOv7 nous remarquons ainsi la différence

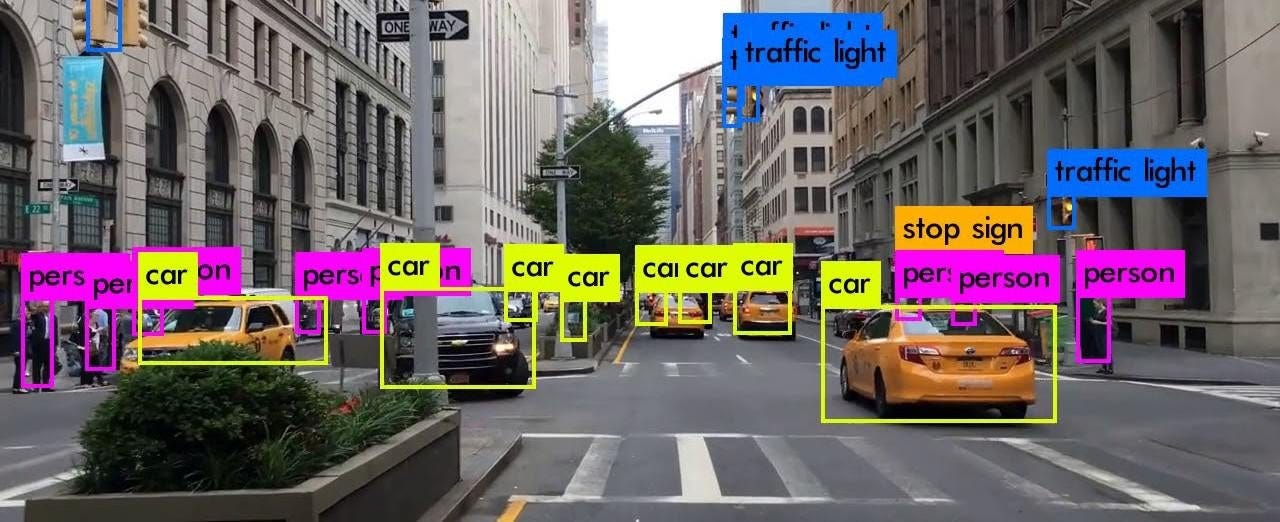
La conception du modèle Detectron a été basée sur l'architecture du modèle Mask R- CNN. En effet, Detectron a été pré-entraîné sur COCO dataset, LVIS dataset ainsi que CityScapes dataset permettant ainsi de faire:
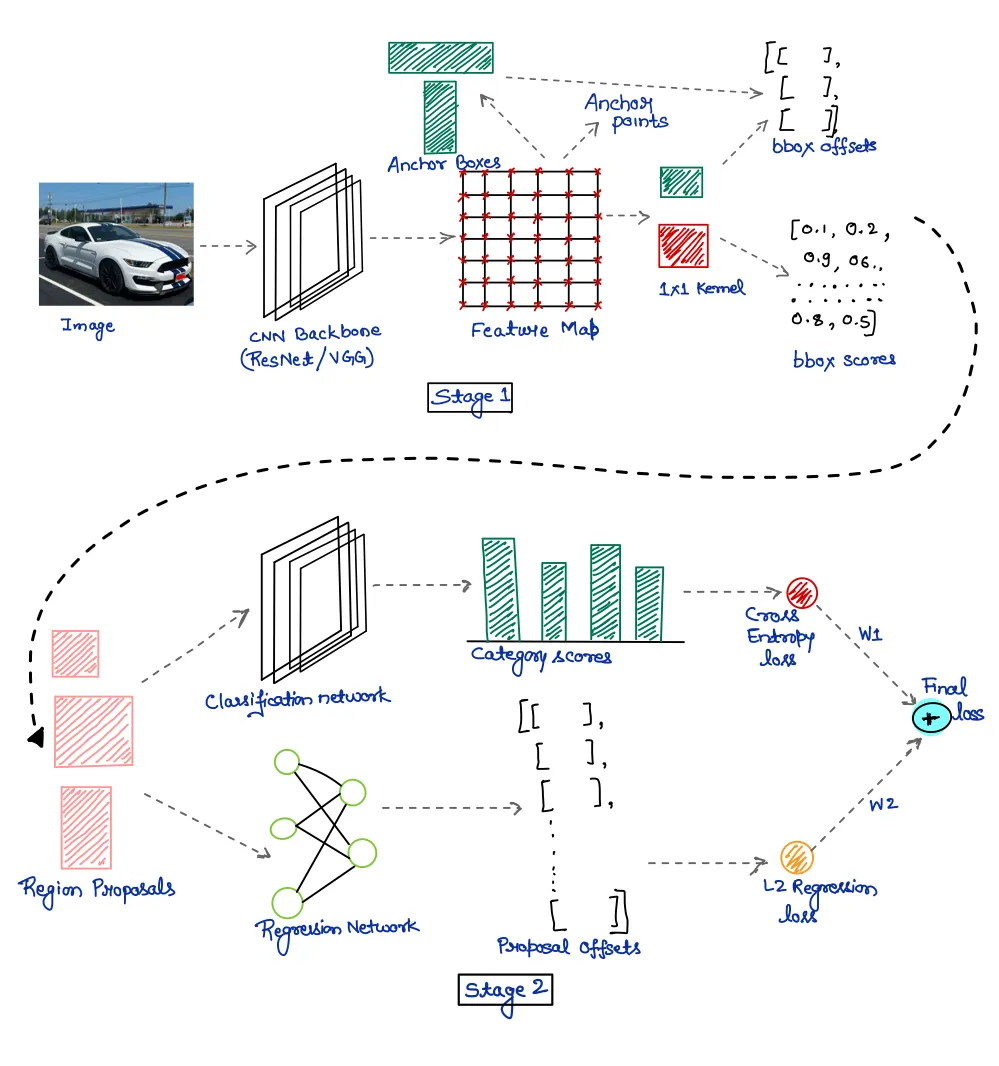
Le modèle Faster R-CNN appartient à la famille R-CNN. En effet, Faster R-CNN est un modèle optimisé du Fast R-CNN et
du R-CNN grâce à l'optimisation du temps de génération des zones d'intérêt qui a été fait en ajoutant un autre
algorithme nommé Region Proposal Networks (RPN): ce réseau de neurones convolutifs supplémentaire permet de générer
directement les propositions de zones. En sortie, le modèle Faster R-CNN produit un label ainsi que les coordonnées
de la zone de l'image contenant l'objet détecté (bounding box).
Vous trouverez ci-joint le notebook contenant les résultats des modèles utilisés avec les différents jeux de données collectés:
D'après ces résultats, nous pouvons souligner que la performance des algorithmes utilisés dépend de plusieurs paramètres: En effet, elle dépend non seulement de la qualité des jeux de données utlisés (taille du dataset, l'angle de la prise des images, nombre d'images par classe etc…) mais aussi du modèle choisi (nombre de couches que comporte chaque modèle, taille du batch, nombre d'epochs utilisés pour l'apprentissage…). Cette performance se manifeste par un temps d'exécution minimal et une meilleure précision de détection et de classification des images. C'est ainsi que nous faisons recours à des technologies comme Tensorboard permettant de visualiser et mesurer le degré de la performance des modèles grâce à des indicateurs comme le mAP,le box_loss, obj_loss, le recall, etc.
https://makina-corpus.com/sig-webmapping/extraction-dobjets-pour-la-cartographie-par-deep-learning-choix-du-modele
http://staff.univ-batna2.dz/sites/default/files/merzougui_ghalia/files/support_de_cours_-deep_learning-chapitre3-cnn.pdf
https://www.ibm.com/fr-fr/cloud/learn/neural-networksIntelligenceartificielle
https://www.lemagit.fr/conseil/Machine-Learning-les-9-types-dalgorithmes-les-plus-pertinents-en-entreprise
https://www.datakeen.co/8-machine-learning-algorithms-explained-in-human-language/
https://azure.microsoft.com/fr-fr/resources/cloud-computing-dictionary/what-are-machine-learning-algorithms/#techniques
https://www-igm.univ-mlv.fr/~dr/XPOSE2014/Machin_Learning/D_Machine_Learning.html
https://datascientest.com
https://wikipedia.org
https://analyticsvidhya.com
